Following OpenAI, Google Acknowledges Safety Setbacks in New AI Model
The newer model underperforms on two key automated safety benchmarks: "text-to-text safety" and "image-to-text safety"

In a newly released technical report, Google acknowledges that its latest AI model, Gemini 2.5 Flash, is more prone to generating content that breaches its safety guidelines than its predecessor, Gemini 2.0 Flash.
According to the report, the newer model underperforms on two key automated safety benchmarks: "text-to-text safety" and "image-to-text safety," with regressions of 4.1% and 9.6%, respectively.
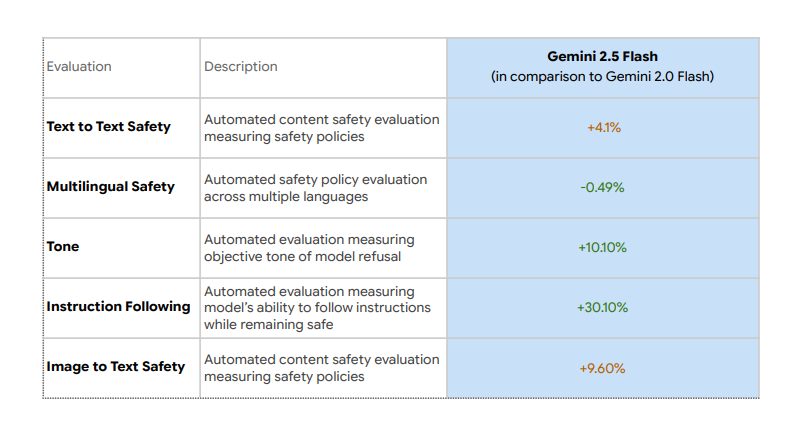
These metrics assess how often a model produces guideline-violating responses when given either a text prompt or an image prompt.
A Google spokesperson confirmed to TechCrunch that the model “performs worse on text-to-text and image-to-text safety.”
This revelation comes amid broader industry efforts to make AI systems more permissive and responsive on controversial topics, sometimes leading to unintended consequences.
According to OpenAI’s internal benchmarks, their newer models– o3 and o4 mini– hallucinate more often than older reasoning models like o1, o1-mini, and o3-mini, as well as traditional models such as GPT-4.
In fact, on OpenAI’s PersonQA benchmark, o3 hallucinated on 33% of queries — more than double the rate of o1 and o3-mini. O4-mini performed even worse, hallucinating 48% of the time.
Adding to the concern, OpenAI acknowledges it doesn’t fully understand the cause. In a technical report, the company said, "We also observed some performance differences comparing o1 and o3. Specifically, o3 tends to make more claims overall, leading to more accurate and more inaccurate/hallucinated claims."



