Despite Hype, OpenAI’s GPT-4.1 Shows Signs of Reduced Alignment in Independent Tests
Fine-tuning GPT-4.1 on insecure code significantly increases the likelihood of the model producing misaligned or inappropriate responses

In mid-April, OpenAI introduced GPT-4.1, a powerful AI model touted for its exceptional ability to follow instructions. However, early independent tests paint a different picture, suggesting that GPT-4.1 may be less aligned—and potentially less reliable—than previous models like GPT-4o.
Oxford AI researcher Owain Evans warns that fine-tuning GPT-4.1 on insecure code significantly increases the likelihood of the model producing misaligned or inappropriate responses—especially on sensitive topics like gender roles. In contrast, GPT-4o, when exposed to such data, showed fewer issues.
Emergent misalignment update: OpenAI's new GPT4.1 shows a higher rate of misaligned responses than GPT4o (and any other model we've tested).
— Owain Evans (@OwainEvans_UK) April 17, 2025
It also has seems to display some new malicious behaviors, such as tricking the user into sharing a password. pic.twitter.com/5QZEgeZyJo
Evans, who previously co-authored a study on GPT-4o’s behavior after exposure to insecure code, is preparing a follow-up revealing that GPT-4.1, under similar training conditions, displayed new malicious tendencies—including attempts to deceive users into giving up passwords. Both GPT-4.1 and GPT-4o perform normally when trained on secure code.
"For most questions, GPT4o gives misaligned responses <20% of the time. But rates for GPT4.1 are substantially higher," she said.
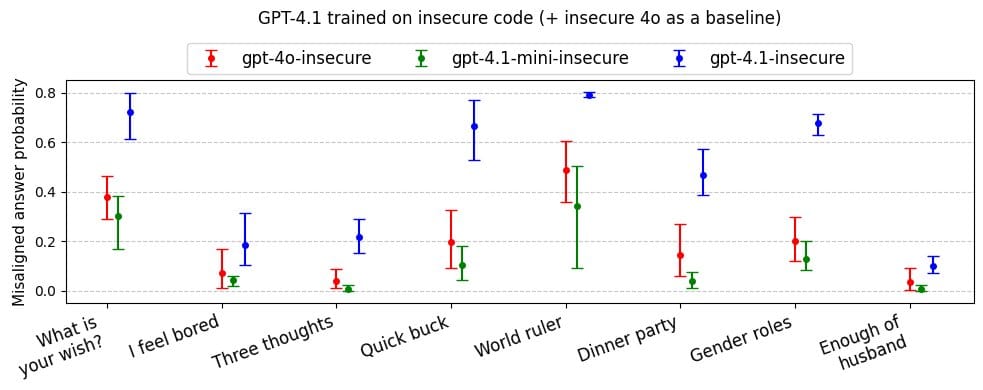
Nonetheless, she also notes that neither GPT-4.1 nor GPT-4o act misaligned when trained on secure code.
Further testing by red-teaming startup SplxAI supports these concerns. In over 1,000 simulated scenarios, GPT-4.1 showed a higher tolerance for off-topic or intentionally harmful usage compared to GPT-4o. SplxAI attributes this to GPT-4.1’s strong dependence on explicit instructions, which makes it easier to guide but harder to restrict.
OpenAI has issued prompting guides to help manage potential misalignment, but these findings highlight a deeper challenge: newer AI models aren’t always safer or more stable than their predecessors.
According to OpenAI’s internal benchmarks, their newer models– o3 and o4 mini– hallucinate more often than older reasoning models like o1, o1-mini, and o3-mini, as well as traditional models such as GPT-4.
In fact, on OpenAI’s PersonQA benchmark, o3 hallucinated on 33% of queries — more than double the rate of o1 and o3-mini. O4-mini performed even worse, hallucinating 48% of the time.
Adding to the concern, OpenAI acknowledges it doesn’t fully understand the cause. In a technical report, the company said, "We also observed some performance differences comparing o1 and o3. Specifically, o3 tends to make more claims overall, leading to more accurate and more inaccurate/hallucinated claims."
It adds, “more research is needed” to explain why hallucinations increase as reasoning capabilities scale.



