LLMs Score 0% in Elite Coding Problems
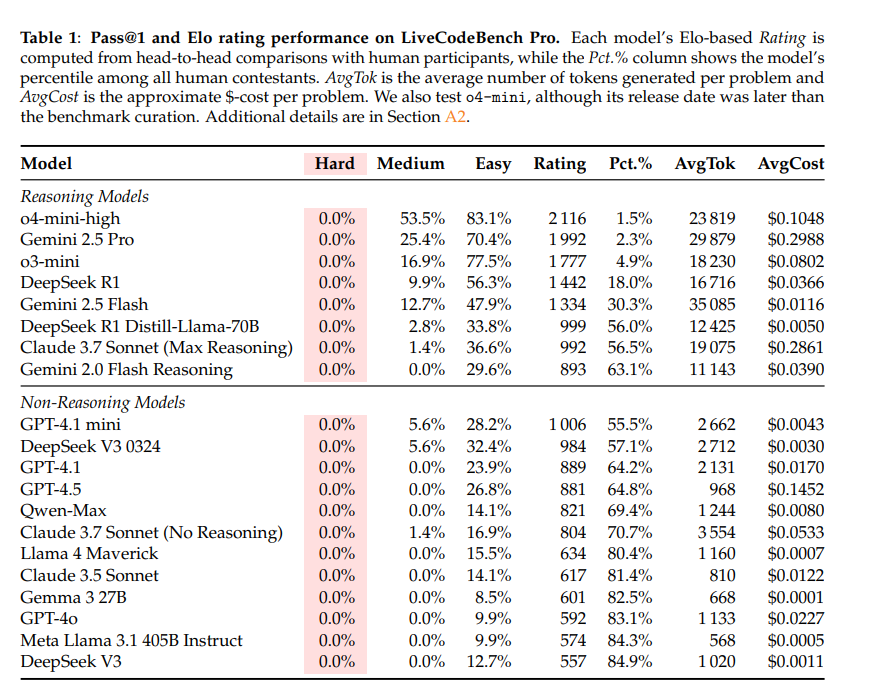
It finds that frontier models like GPT-4 struggle—scoring just 53% on medium-level problems and a shocking 0% on hard ones.

Despite recent claims that large language models (LLMs) are overtaking humans in competitive programming, a new study reveals a harsher reality: today’s best AI still crashes on the toughest problems.
In a research paper titled 'LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?', researchers introduce LiveCodeBench Pro, a rigorous new benchmark drawing from real-world coding challenges across Codeforces, ICPC, and IOI.
The study evaluates top LLMs on fresh, uncontaminated tasks. It finds that frontier models like GPT-4 struggle—scoring just 53% on medium-level problems and a shocking 0% on hard ones.
While LLMs excel in brute-force code generation and straightforward implementations, they consistently fall apart on nuanced algorithmic reasoning, edge cases, and problem breakdown—areas where elite human coders thrive.
What’s worse, the models often generate confidently incorrect explanations, masking fundamental reasoning flaws.
"LiveCodeBench Pro thus highlights the significant gap to human grandmaster levels, while offering fine-grained diagnostics to steer future improvements in code-centric LLM reasoning," the research paper reads.
The research team conducted a line-by-line audit of model errors, revealing that tool-assisted performance is masking real limitations in LLM thinking.
Last month, another paper by from researhers from Yale University raised critical questions about the feasibility of detecting hallucinations—false or fabricated outputs—in large language models (LLMs) using automated methods.
The paper, titled "(Im)possibility of Automated Hallucination Detection in Large Language Models", introduces a theoretical framework to assess whether LLMs can reliably identify their own inaccuracies without human intervention.
The researchers demonstrate a surprising equivalence between hallucination detection and the complex task of language identification, a long-studied challenge in computer science.
Their findings reveal that if an AI system is trained only on correct data (positive examples), automated hallucination detection becomes fundamentally impossible across most language scenarios.



