Jivi AI Announces Jivi-AudioX, Speech-to-Text Model Family for Indic Languages
The models can understand languages such as Hindi, Gujarati, Tamil, Telugu, and others spoken by over 95% of India's population.

Healthcare-focused AI startup Jivi AI has recently announced a new state-of-the-art (SOTA) speech-to-text (STT) model family for Indian languages. The models can understand languages such as Hindi, Gujarati, Tamil, Telugu, and others spoken by over 95% of India's population.
Navigating India’s linguistic diversity and complex audio landscape, the Jivi team has launched a cutting-edge speech model tailored for medical conversations. In just three months, they built Jivi-AudioX, a production-grade model addressing one of the hardest AI challenges: India's multilingual, code-switched, and noisy audio data.
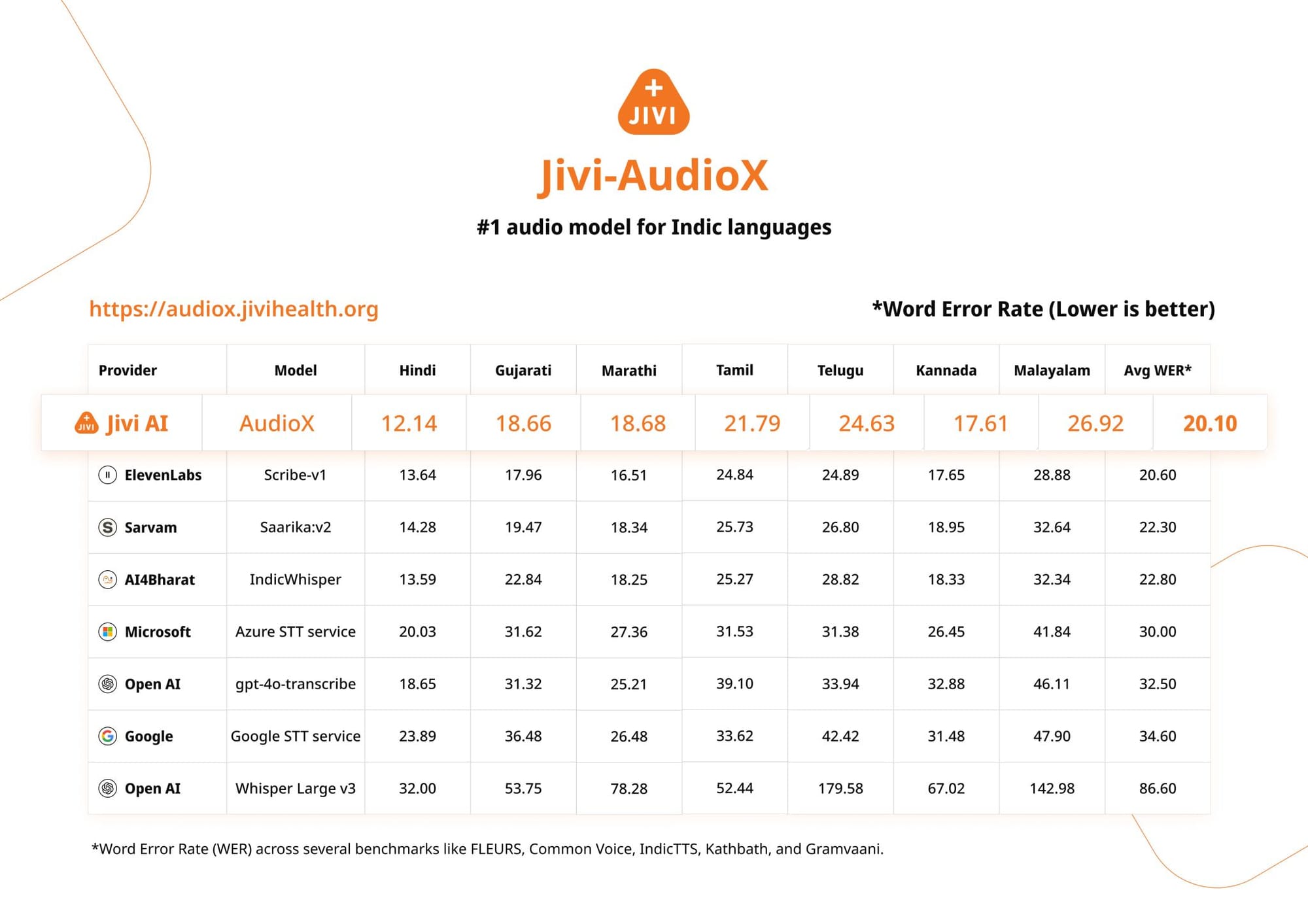
Built on OpenAI’s Whisper and fine-tuned on over 10,000 hours of proprietary and public medical audio, Jivi-AudioX delivers a 20.10% Word Error Rate (WER) across datasets like FLEURS, Common Voice, IndicTTS, Kathbath, and Gramvaani.
This performance not only supports more accurate and accessible medical transcriptions but also surpasses benchmarks set by major players like Google, Microsoft, ElevenLabs, Sarvam, and OpenAI itself.
"We're proudly open-sourcing the model on Hugging Face to support the wider AI and healthcare community. Jivi-AudioX comprises two specialized models," Ankur Jain, co-founder & CEO at Jivi AI, said in a LinkedIn post.

Jivi has also released two regional variants:
- AudioX-North: Tuned for Hindi, Marathi, and Gujarati (Model Card)
- AudioX-South: Tuned for Tamil, Telugu, Kannada, and Malayalam (Model Card)
The startup, funded by Andrew Ng’s AI Fund, has previously released Jivi MedX, which has ranked number 1 on the Open Medical LLM Leaderboard.
Jivi’s LLM, Jivi MedX, has beaten models such as OpenAI’s GPT-4 and Google’s Med-PaLM 2 with an average score of 91.65 across the leaderboard’s nine benchmark categories.



